I just released version 0.5 of Ruby PDNS. This mainly introduces a full statistics capability and fixes a minor bug or two.
I didn’t intend on releasing another version before 1.0 but it turns out the stats feature were quite a big job worthy of a release.
The stats is complicated by the fact that PDNS runs multiple instances of my code sharing the load between them, this makes keeping stats pretty hard because I have no shared memory space like you would in a multi threaded app. So I’d somehow need to dump per process stats and calculate totals. Everyone I asked suggested writing a log and summarizing the log data but this just never felt right to me – there would be issues with log rotation and knowing till when you last counted stats and so forth – so I kept looking for a solution.
I struggled to come up with a good approach for a long time, finally settling on each process writing a YAML file with it’s stats and a cron job to aggregate it regularly. This turned out to be quite elegant – much more so than processing logs for example – as the cron job cleans up files it already processed and also ignore too old ones etc. If the cron job keeps running it should be zero maintenance.
I added a script – pdns-get-stats.rb – to query the aggregated stats:
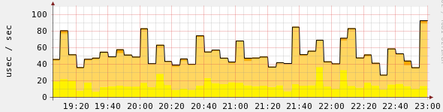
The puppet record is using GeoIP so you’d expect it to be a bit slower than ones that just shuffle records and this is clear above, though I am quite pleased with the performance of the GeoIP code. Times are in microseconds.
Those who know Cacti will recognise the format as being compatible with the Cacti plugin standard – if there is demand I can easily add Munin, Collectd etc query tools
Using the details I was able to draw a quick little graph below using Cacti
The next major step is to write a API that is externally accessible, perhaps using REST over HTTP, this means you could send data from your monitoring or CMDB and adjust weights or really anything you can code using external data.
Puppet supports something called Modules, it’s a convenient collection of templates, files, classes, types and facts all related to one thing. I find it makes it easy to think about a problem in an isolated manner and it should be the default structure everyone use.
Usually though the problem comes with how to lay out modules and how to really use the Puppet classes system, below a simple module layout that can grow with you as your needs extend. I should emphasis the simple here – this example does not cater well for environments with mix of Operating Systems, or weird multi site setups with overrides per environment, but once you understand the design behind this you should be able to grow it to cater for your needs. If you have more complex needs, see this post as a primer on using the class relationships effectively.
For the most part I find I make modules for each building block – apache, syslog, php, mysql – usually the kind of thing that has:
One or more packages – or at least some install process.
One or more config files or config actions
A service or something that you do to start it.
You can see there’s an implied dependency tree here, the config steps require the package to be installed and the service step require the config to be done. Similarly if any config changes the services might need to restart.
We’d want to cater for the case where you could have 10 config files, or 10 packages, or 100s of files needed to install the service in question. You really wouldn’t want to create a big array of require => resources to control the relationships or to do the notifications, this would be a maintenance nightmare.
We’re going to create a class for each of the major parts of the module – package, config and service. And we’ll use the class systems and relationships, notifies etc to ensure the ordering, requires and notifies are kept simple – especially so that future changes can be done in one place only without editing everywhere else that has requires.
If we now just do include ntp everything will happen cleanly and in order.
There’s a few things you should notice here. We’re using the following syntax in a few places:
require => Class[“ntp::something”]
notify => Class[“ntp::service”]
before => Class[“ntp::something”]
subscribe => Class[“ntp::config”]
All of the usual relationship meta parameters can operate on classes, so what this means is if you require Class[“ntp::config”] then both ntp.conf and step-tickers will be created before the service starts without having to list the files in your relationships. Similarly if you notify a class then all resources in that class gets notifies.
The preceding paragraph is very important to grasp, typically we’d try to maintain arrays of files in require trees and later if we add a new config file we have to go hunt everywhere that needs to require it and update those places, by using this organization approach we never have to update anything. If I add 10 services and 100 files into the config and service classes everything else that requires ntp::service will still work as expected without needing updates.
This is a very important decoupling of class contents with class function. Your other classes should never be concerned with class contents only class function.
As a convention this layout is a good sample, if all your daemons gets installed in the daemon::install class you’ll have no problem knowing where to find the code to adjust the install behavior – perhaps to upgrade to the next version – you should try to come up with a set of module naming conventions that works for you and stick to it throughout your manifests – I have a rake task to setup my usual module structure, they’re all the same and the learning curve for new people is small.
By building up small classes that focus on their task or subtask you can build up ever more powerful modules. We have a simple example here, but you can see how you could create ntp::master and ntp::client wrapper classes that would simply reuse the normal ntp::install and ntp::service classes.
As I mentioned this is a simple example for simple needs, the real take away here is to use class relationships and decouple the contents of those classes with their intent this should give you a more maintainable code set.
Ultimately conventions such as these will be needed to get us all one step closer to being able to share modules amongst each other as the specifics of making Apache on different distributions work will not matter – we’d just know that we want Class[“apache::service”] for example.
I use vim for almost all my editing needs, till now I often thought I should give using TextMate another try due to the nice Bundle that Masterzen made but there’s just something about desktop editing that puts me off.
I’ve also been renewing my efforts to better my VIM use and came across the excellent snipMate that enables you to do almost the same thing as textmate – the syntax for the snippets is even roughly the same.
I made a quick snippet file this morning for some common used bits that you can find here, see it in action below or view the movie better here:
Each time you see the input cursor jump between fields in the templates I’m simply pressing tab, shift-tab would cycle backward.
There are some nice things here you might not notice, for example editing a file test.pp and adding a class it will automatically fill in the class name as test. Same for nodes, it’s really very powerful and the snippets are trivial to write.
I am using the vim syntax file that comes in the puppet tarball and the adaryn color scheme that ships with vim.
Since moving into my current flat I’ve not really had a convenient place to develop film so have been putting the black and white shooting on the backburner.
During the last week though I for some other reason thought to ask the Snappy Snaps near me and sure enough they did do 120 black and white. Problem is they wanted £18/roll developed and scanned and want 3 days to do it in.
So I asked around and found out that the Snappy Snaps in Wardour Street London does it for £10/roll scanned on a standard 1 hour wait, that’s very good.
Below a scan direct from their scanner, I didn’t touch it in any way (click for full size):
You can see some more from this roll here it was taken on Ilford FP4 with my Bronica SQA, this is also the first time in over a year that I touched this camera so was fumbling around a bit, will get back into it now I think especially with a quick development place just 5 minutes from my office.
First some metrics from the puppetmaster before and after, this particular master handles around 50 clients on a 30 minute interval. The master is a Mongrel + Apache master with 4 worker processes running on a 64bit CentOS 5.3 VM with 1GB RAM
First the CPU graph, blue is user time red is system time:
The next is Load Average, it’s a stack of 5, 10 and 15 minute averages:
And finally here is a bandwidth of the master blue is outbound and green is incoming:
So this is the master, it’s very interesting that the master is a lot busier than before, even with just 50 nodes this is a significant CPU increase, I do not know how this will map to say 500 or 600 nodes but I think larger sites will want to be pretty careful about updating a large chunk of machines without testing the impact.
Finally here is a graph from a node, the node has 450 file resources and doesn’t do anything but run Puppet all day – at night in this graph for a short period it did backups after that it idled again. In this case combined with the massive drop in run time the cpu time is also way down, I think this is a massive win – you can always add more masters easily but suffering on all your nodes under puppetd is pretty bad. This on its own for me is a pretty big win for upgrading to Puppet 0.25.
This graph is obviously taken some hours later but it’s the same basic scale.
I did not see a noticeable change in memory profile on either master of nodes so no graphs included here for that.
Overall I think this is a big win, but be careful of what happens on your masters when you upgrade.