Previously I blogged about rebuilding my personal infra, focussing on what I had before.
Today we’ll start into what I used to replace the old stuff. It’s difficult to know where to start but I think a bit about VM and Container management is as good as any.
Kubernetes
My previous build used a 3 node Kubernetes Cluster hosted at Digital Ocean. It hosted:
- Public facing websites like this blog (WordPress in the past), Wiki, A few static sites etc
- Monitoring: Prometheus, Grafana, Graphite
- A bridge from The Things Network for my LoRaWAN devices
- 3 x redundant Choria Brokers and AAA
- Container Registry backed by Spaces (Digital Ocean object storage)
- Ingress and Okta integration via Vouch
- Service discovery and automatic generation of configurations for Prom, Ingress etc
Apart from the core cluster I had about 15 volumes, 3 Spaces, an Ingress load balancer with a static IP and a managed MySQL database.
I never got around to go full GitOps on this setup, it just seemed too much to do for a one man infra to both deploy all that and maintain the discipline. Of course I am not a stranger to the discipline required being from Puppet world, but something about the whole GitOps setup just seemed like A LOT.
I quite liked all of this, when Kubernetes works it is a pleasant experience, some highlights:
- Integration with cloud infra like LBs is an amazing experience
- Integration with volumes to provide movable storage is really great and hard to repeat
- I do not mind YAML and the diffable infrastructure is really great, no surprise there. I hold myself largely to blame for the popularity of YAML in infra tools at large thanks to Hiera etc, so I can’t complain.
- Complete abstraction of node complexities is a double-edged sword but I think in the end I come to appreciate it
- I do like the container workflow and it was compatible with some pre-k8s thoughts I had on this
- Easy integration between CI and infrastructure with the
kubectl rolloutabstraction
Some things I just did not like, I will try to mention some things that not the usual gripes:
- Access to managed k8s infra is great, but not knowing how its put together for the particular cloud can make debugging things hard. I had some Cilium failures that was a real pain
- API deprecations are constant, production software rely on Beta APIs and will just randomly break. I expected this, but over the 3 years this happened more than I expected. You really have to be on top of all the versions of all the things
- The complimentary management tooling is quite heavy like I mentioned around GitOps. Traditional CM had a quick on-ramp and was suitable at small scale, I miss that
- I had to move from Linode K8s to Digital Ocean K8s. The portability promises of pure kubernetes is lost if you do not take a lot of care
- Logging from the k8s infra is insane, ever-changing, unusable unless you really really are into this stuff like very deep and very on-top of every version change
- Digital Ocean does forced upgrades of the k8s, this is fine. The implication is that all the nodes will be replaced so Prometheus polling source will change with big knock on effect. The way DO does it though involves 2 full upgrades for every 1 upgrade doubling the pain
- It just seem like no-one wants to even match the features Hiera have in terms of customization of data
- Helm
In the end it all just seemed like a lot for my needs and was ever slightly fragile. I went on a 3 month sabbatical last year and the entire infra went to hell twice, all on its own, because I neglected some upgrades during this time and when Digital Ocean landed their upgrade it all broke. It’s a big commitment.
See the full entry for detail of what I am doing instead.
Container Management
So let’s look at what I am working on for container management. My current R&D focus in Choria is around Autonomous Agents that can manage one thing forever, one thing like a Container. So I am dog-fooding some of this work where I need containers and will move things into containers as I progress down this path.
Looking at my likes list from the Kubernetes section above we can imagine where I am focussing with the tooling I am building, lets just jump right in with what I have today:
containers:
tally:
image: registry.choria.io/choria/tally
image_tag: latest
syslog: true
kv_update: true
restart_files:
- /etc/tally/config/choria.conf
volumes:
- /etc/tally/config:/tally/config
ports:
- 9010:8080
register_ports:
- protocol: http
service: tally
ip: %{facts.networking.ip}
cluster: %{facts.location}
port: 9010
priority: 1
annotations:
prometheus.io/scrape: true
This is Puppet Hiera data that defines:
- A running Container for a Choria related service that passively listens to events and expose metrics to Prometheus
- It will watch a file on the host file system and restart the container if the file changes, Puppet manages the file in question
- It supports rolling upgrades via Key-Value store updates but defaults to
latest - It exposes the port to service discovery with some port specific annotations
This creates a Choria Autonomous Agent that will forever manage the container. If health checks fail the port will not be published to Service Discovery anymore and remediation will kick in etc.
Of course Puppet is an implementation detail - anything that can press the YAML file and place it into Choria can do this. Choria can also download and deploy these automations as a plugin at runtime via securely signed artifacts. So this supports a fully CI/CD driven GitOps like flow that has no Puppet involvement.
To replace the kubectl rollout process I support KV updates like choria kv put HOIST container.tally.tag 0.0.4 (we have Go APIs for this also), the container will listen for this kv update and perform an upgrade. Upgrades support rolling strategies like say 2 at at time out of a cluster of 20 etc. The kv put is the only interaction needed to do this and no active orchestration is needed.
Service discovery is also in a Choria Key-Value bucket and I can query it:
$ sd find
[1] tally @ ve2 [http://192.168.1.10:9010]
prometheus.io/port: 9010
Or generate Prometheus configurations:
$ sd prometheus
- targets:
- 192.168.1.10:9010
labels:
__meta_choria_cluster_name: ve2
__meta_choria_ip: 192.168.1.10
__meta_choria_port: "9010"
__meta_choria_priority: "1"
__meta_choria_protocol: http
__meta_choria_service: tally
So one can imagine how that integrates with Prometheus file based SD or HTTP based. In future I’ll add things to manage ingress configurations automatically etc, and of course Service Discovery -> file flow can ge managed using Autonomous Agents also.
Actual building of containers have not changed much from earlier thoughts about this and the above system - called Hoist - will focus on strengthening those thoughts.
Virtualization
Previously I ran some various mixes of KVM things: I had Puppet code to generate libvirt configuration files, later I got lazy and used the RedHat graphical machines manager - I just don’t change my VMs much to be honest so don’t need a lot of clever things.
As I was looking to run 3 or 4 baremetal machines with VMs on-top I wanted something quite nice with a nice UI and started looking around and found numerous Youtubers going on like crazy about Proxmox. I tried Proxmox for a week on some machines and had some thoughts about this experience.
It is nice with a broad feature set that is quite a good all round product in this space, I can see if done right this will be formidable tool to use and would consider it in future again.
Is seems like this is a company who has engineers, paid to engineer, and they will engineer things all day long. Ditto product owners etc. There’s a lot there and lots of it feels half-baked, awkward or incomplete or in-progress. Combined with there just being A LOT it seemed like a mess. I bet this is a company who just love sprint based work and fully embrace the sprints being quite isolated approach. It shows in obvious ways.
It’s Debian based. I have used EL from their first Beta. Slackware before. SLS before (1993!). In kubernetes you can get away with not caring so much about your hosts but in a virtualized environment you will need to make sure you have ways to manage updates, backups and such of those baremetals. I do not have any tooling specifically built for Debian so I really do not want that lift. I also just do not care even remotely for Debian or its community.
Ultimately I do not need integration with Ceph etc, I don’t need (oh hell no do I not need) a database-driven file system developed by Proxmox and for my needs I do not need SDN. All these things are useful but it seemed like it would tick some of the boxes I listed in Kubernetes conns.
After some looking around at options I came across Cockpit which comes integrated already into EL based distros and while it’s not as full featured as Proxmox I find that to be a feature rather than a shortcoming. It does just the right things and I can easily just not install things I do not want.
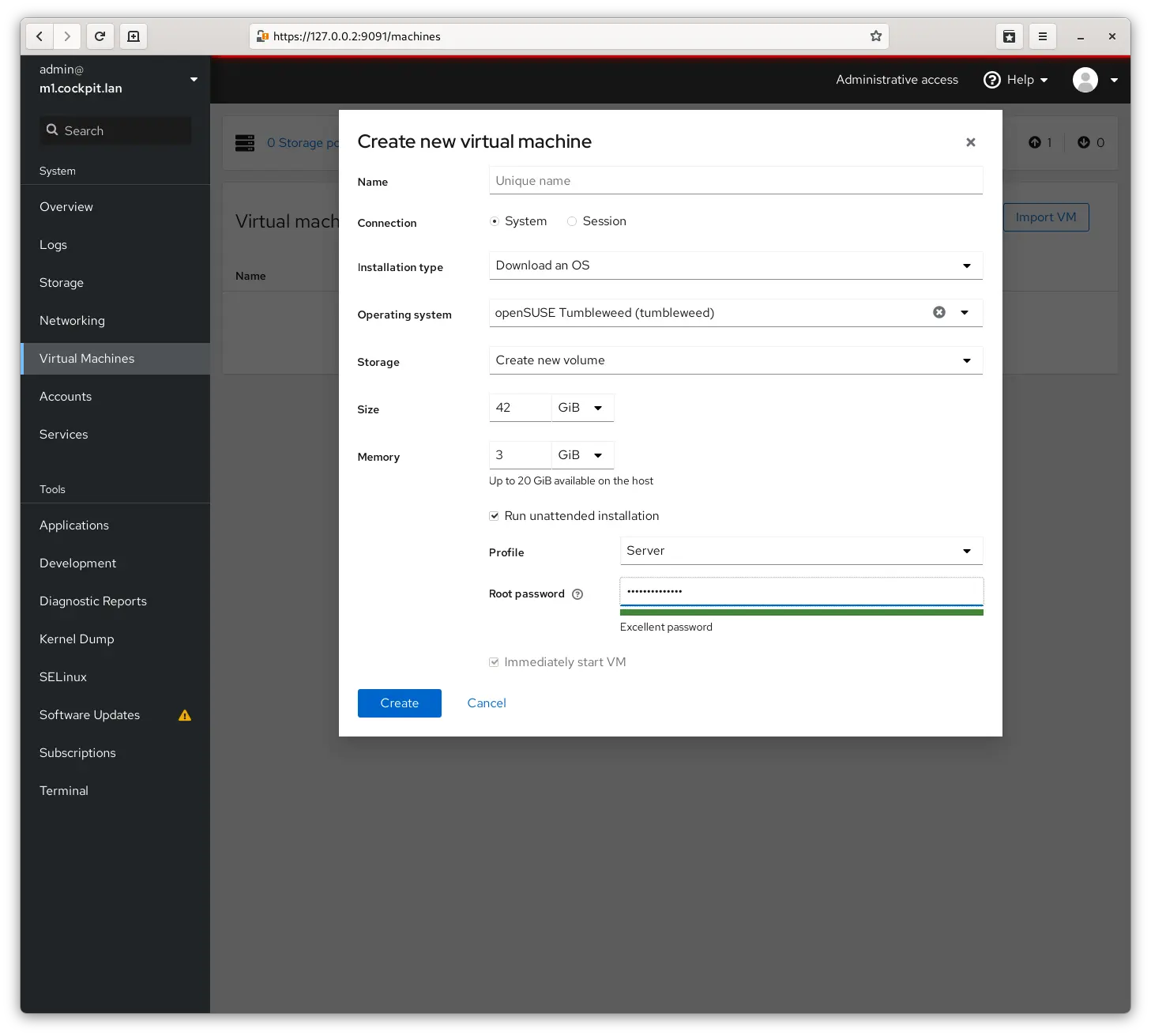
I think its firewall management needs a bunch of work still, but that’s ok I do not want to manage firewalls in this manner (more later) so that is just fine, I also do not need its package management - no problem, just uninstall the feature.
Really not much to say or complain about here - and having nothing to say is a huge feature - it makes virtual machines, allow me to edit their configurations, see their consoles etc. Just what I need and no more. One annoying thing with it is that I cannot figure out how to trigger a re-install of a machine, I did not look too deep though.
EDIT: I do have a few things to say about it after all:
- It took like 2 minutes to install on an EL machine.
- When you are not using it, there is nothing in the process tree. It’s fully based on socket activation. No resources wasted.
- It does not take over and camp on everything. It uses the same commands and APIs Puppet/Ansible/You does, you can keep using CLI tools you know. Or progressively learn.
- It uses your normal system users via PAM so not much to deploy regarding authentication etc.
- It support EL/Debian/Ubuntu and more.
This is huge, it just is super lightweight and gets out of your way and does not prescribe much. It does not invent new things and does not invent new terminology. Huge.
Conclusion
So that is roughly what I am doing for Virtualization and Container management after Kubernetes. Container management is a work in progress so a lot of my components are now just stuff running on VMs but as I progress to improve Hoist a bit I’ll gradually move into it for more things, this has been something I’ve wanted to finish for a long time so I am glad to get the chance.
Further as my Lab is really that after all, a place for R&D, using the area I am focussing on in Choria in anger to solve some real problems has been invaluable and I wanted more of that, this influenced some of these decisions.