by R.I. Pienaar | Apr 4, 2011 | Code
I’ve been working on rewriting my proof of concept code into actual code I might not feel ashamed to show people, this is quite a slow process so hang in there.
If you’ve been reading my previous posts you’ll know I aim to write a framework for monitoring and event correlation. This is a surprisingly difficult problem space mostly due to the fact that we all have our own ideas of how this should work. I will need to cater literally for all kind of crazy to really be able to call this a framework.
 In the most basic form it just take events, archive them, process metrics, process status and raise alerts. Most people will recognize these big parts in their monitoring systems but will also agree there is a lot more to it than this. What describes the extra bits will almost never be answered in a single description as we all have unique needs and ideas.
In the most basic form it just take events, archive them, process metrics, process status and raise alerts. Most people will recognize these big parts in their monitoring systems but will also agree there is a lot more to it than this. What describes the extra bits will almost never be answered in a single description as we all have unique needs and ideas.
The challenge I face is how to make an architecture that can be changed, be malleable to all needs and in effect be composable rather than a prescribed design. These are mostly solved problems in computer science however I do not wish to build a system only usable by comp sci majors. I want to build something that infrastructure developers (read: DevOps) can use to create solutions they need at a speed reaching proof-of-concept velocity while realizing a robust result. These are similar to the goals I had when designing MCollective.
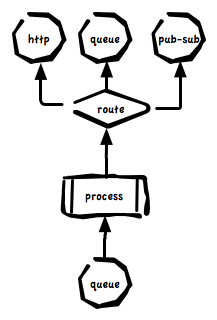
In building the rewrite of the code I opted for this pattern and realized it using middleware and a simple routing system. Routing in middleware is very capable like this post about RabbitMQ describes but this is only part of the problem.
Given the diagram above and given that events can be as simple as a metric for load and as complex as a GitHub commit notify containing sub documents for 100s of commits and can be a mix of metrics, status and archive data we’d want to at least be able to configure these behaviors and 100s like them:
- Only archive a subset of messages
- Only route metrics for certain types of events into Graphite while routing others into OpenTSDB
- Only do status processing on events that has enough information to track state
- Dispatch alerts for server events like load average alerts to a different system than alerts for application level events like payments per hour below a certain threshold. These are often different teams with different escalation procedures.
- Dispatch certain types of metrics to a system that will do alerting based on real time analysis of past trends – this is CPU intensive and you should only subject a subset of events to this processing
- Route a random 10% of the firehose of events into a development environment
- Inject code – in any language – in between 2 existing parts of the event flow and alter the events of route them to a temporary debugging destination.
We really need a routing system that can plug into any part of the architecture and make decisions based on any part of the event.
I’ve created a very simple routing system in my code that plugs all the major components together. Here’s a simple route that sends metrics off to the metric processor. It transforms events that contain metrics into graphite data:
add_route(:name => "graphite", :type => ["metric", "status"]) do |event, routes|
routes << "stomp:///queue/events.graphite" unless event.metrics.empty?
end |
add_route(:name => "graphite", :type => ["metric", "status"]) do |event, routes|
routes << "stomp:///queue/events.graphite" unless event.metrics.empty?
end
You can see from the code that we have access to the full event, a sample event is below, and we can make decisions based on any part of the event.
{"name":"puppetmaster",
"eventid":"4d9a33eb2bce3479f50a86e0",
"text":"PROCS OK: 2 processes with command name puppetmasterd",
"metrics":{},"tags":{},
"subject":"monitor2.foo.net",
"origin":"nagios bridge",
"type":"status",
"eventtime":1301951466,
"severity":0} |
{"name":"puppetmaster",
"eventid":"4d9a33eb2bce3479f50a86e0",
"text":"PROCS OK: 2 processes with command name puppetmasterd",
"metrics":{},"tags":{},
"subject":"monitor2.foo.net",
"origin":"nagios bridge",
"type":"status",
"eventtime":1301951466,
"severity":0}
This event is of type status and has no metrics so it would not have been routed to the graphite system, while the event below has no status only metrics:
{"name":"um.bridge.nagios",
"created_at":1301940072,
"eventid":"4d9a34462bce3479f50a8839",
"text":"um internal stats for um.bridge.nagios",
"metrics":{"events":49},
"tags":{"version":"0.0.1"},
"subject":"monitor2.foo.net",
"origin":"um stat",
"type":"metric",
"extended_data":{"start_time":1301940072},
"eventtime":1301951558,"severity":0} |
{"name":"um.bridge.nagios",
"created_at":1301940072,
"eventid":"4d9a34462bce3479f50a8839",
"text":"um internal stats for um.bridge.nagios",
"metrics":{"events":49},
"tags":{"version":"0.0.1"},
"subject":"monitor2.foo.net",
"origin":"um stat",
"type":"metric",
"extended_data":{"start_time":1301940072},
"eventtime":1301951558,"severity":0}
By simply supplying this route:
add_route(:name => "um_status", :type => ["status", "alert"]) do |event, routes|
routes << "stomp:///queue/events.status"
end |
add_route(:name => "um_status", :type => ["status", "alert"]) do |event, routes|
routes << "stomp:///queue/events.status"
end
I can be sure this non status bearing event of type metric wouldn’t reach the status system where it will just waste resources.
You can see the routing system is very simple and sit at the emitting side of every part of the system. If you wanted to inject code between the main Processor and Graphite here simply route the events to your code and then back into graphite when you’re done transforming the events. As long as you can speak to middleware and process JSON you can inject logic into the flow of events.
I hope this will give me a totally composable infrastructure, I think the routes are trivial enough that almost anyone can write and tweak them and since I am using the most simplest of technologies like JSON almost any language can be used to plug into this framework and consume the events. Routes can be put into the system without restarting anything, just drop the files down and touch a trigger file – the routes will immediately become active.
The last example I want to show is the development route I mentioned above that siphons off roughly 10% of the firehose into your dev systems:
add_route(:name => "development", :type => "*") do |event, routes|
routes << "stomp:///topic/development.portal" if rand(10) == 1
end |
add_route(:name => "development", :type => "*") do |event, routes|
routes << "stomp:///topic/development.portal" if rand(10) == 1
end
Here I am picking all event types, I am dumping it into a topic called development.portal but only in roughly 10% of cases. We’re using a topic since they dont buffer or store or consume much memory when the development system is down – events will just be lost when the dev system is down.
I’d simply drop this into /etc/um/routes/portal/development.rb to configure my production portal to emit raw events to my development event portal.
That’s all for today, as mentioned this stuff is old technology and nothing here really solves new problems but I think the simplicity of the routing system and how it allows people without huge amounts of knowledge to re-compose code I wrote in new and interesting ways is quite novel in the sysadmin tool space that’s all too rigid and controlled.
by R.I. Pienaar | Mar 25, 2011 | Code
Since my last post I’ve spoken to a lot of people all excited to see something fresh in the monitoring space. I’ve learned a lot – primarily what I learned is that no one tool will please everyone. This is why monitoring systems are so hated – they try to impose their world view, they’re hard to hack on and hard to get data out. This served only to reinforce my believe that rather than build a new monitoring system I should build a framework that can build monitoring systems.
DevOps shops who can cut code, should be able to build the monitoring they want, not the monitoring their vendor thought they want.
Thus my focus has not been on how can I declare relationships between services, or how can I declare an escalation matrix. My focus has been on events and how events relate to each other.
Identifying an Event
Events can come from many places, in the recent video demo I did you saw events from Nagios and events from MCollective. I also have event bridges for my Apache Blackbox, SNMP Traps and it would be trivial to support events from GitHub commit hooks, Amazon SNS and really any conceivable source.
Events need to be identified then so that you can send information related to the same event from many sources. Your trap system might raise a trap about a port on a switch but your stats poller might emit regular packet counts – you need to know these 2 are for the same port.
You can identify events by subject and by name together they make up the event identity. Subject might be a FQDN of a host and name might be load or cpu usage.
This way if you have many ways to input information related to some event you just need to identify them correctly.
Finally as each event gets stored they get given a unique ID that you can use to pull out information about just a specific instance of an event.
Types Of Event
I have identified a couple of types of event in the first iteration:

- Metric – An event like the time it took to complete a Puppet run or the amount of GET requests served by a vhost
- Status – An event associated with an up/down style state transition, can optional embed a metrics event
- Archive – An event that you just wish to archive along with others for later correlation like a callback from GitHub saying code was comitted and by whom
The event you see on the right is a metric event – it doesn’t represent one specific status and it’s a time series event which in this case got fed into Graphite.
Status events get tracked automatically – a representation is built for each unique event based on its subject and name. This status representation can progress through states like OK, Warning, Critical etc. Events sent from many different sources gets condensed and summarized into a single status representing how that status looks based on most recent received data – regardless of source of the data.
Each state transition and each non 0 severity event will raise an Alert and get routed to a – pluggable – notification framework or frameworks.
Event Associations and Metadata
Events can have a lot of additional data past what the framework needs, this is one of the advantages of NoSQL based storage. A good example of this would be a GitHub commit hook. You might want to store this and retain the rich data present in this event.
My framework lets you store all this additional data in the event archive and later on you can pick it up based on event ID and get hold of all this rich data to build reactive alerting or correction based on call backs.
Thanks to conversations with @unixdaemon I’ve now added the ability to tag events with some additional data. If you are emitting many events from many subsystems out of a certain server you might want to embed into the events the version of software currently deployed on your machine. This way you can easily identify and correlate events before and after an upgrade.
Event Routing
So this is all well and fine, I can haz data, but where am I delivering on the promise to be promiscuous with your data routing it to your own code?
- Metric data can be delivered to many metrics emitters. The Graphite one is about 50 lines of code, you can run many in parallel
- Status data is stored and state transitions result in Alert events. You can run many alert receivers that implement your own desired escalation logic
For each of these you can write routing rules that tell it what data to route to your code. You might only want data in your special metrics consumer where subject =~ /blackbox/.
I intent to sprinkle the whole thing with a rich set of callbacks where you can register code that declares an interest in metrics, alerts, status transitions etc in addition to the big consumers.
You’d use this code to correlate the amount of web requests in a metric with the ones received 7 days ago. You can then decide to raise a new status event that will alert Ops about trend changes proactively. Or maybe you want to implement your own auto-scaler where you’d provision new servers on demand.
Scaling
How does it scale? Horizontally. My tests have shown that even on a modest (virtual) hardware I am able to process and route in excess of 10 000 events a minute. If that isn’t enough you can scale out horizontally by spreading the metric, status and callback processing over multiple physical systems. Each of the metric, status and callback handlers can also scale horizontally over clusters of servers.
Bringing It All Together
So to show that this isn’t all just talk, here are 2 graphs.

This graph shows web requests for a vhost and the times when Puppet ran.

This graph shows Load Average for the server hosting the site and times when Puppet ran.
What you’re seeing here is a correlation of events from:
- Metric events from Apache Blackbox
- Status and Metric events for Load Averages from Nagios
- Metric events from Puppet pre and post commands, these are actually metrics of how long each Puppet run was but I am showing it as a vertical line
This is a seemless blend of time series data, status data and randomly occurring events like when Puppet runs, all correlated and presented in a simple manner.
by R.I. Pienaar | Mar 19, 2011 | Uncategorized
I’ve been Tweeting a bit about some prototyping of a monitoring tool I’ve been doing and had a big response from people all agreeing something has to be done.
Monitoring is something I’ve been thinking about for ages but to truly realize my needs I needed mature discovery based network addressing and ways to initiate commands on large amounts of hosts in a parallel manner. I have this now in the MCollective and I feel I can start exploring some ideas of how I might build a monitoring platform.
I won’t go into all my wishes, but I’ll list a few big ones as far as monitoring is concerned:
- Current tools represent a sliding scale, you cannot look at your monitoring tool and ever know current state. Reported status might be a window of 10 minutes and in some cases much longer.
- Monitoring tools are where data goes to die. Trying to get data out of Nagios and into tools like Graphite, OpenTSDB or really anywhere else is a royal pain. The problem get much harder if you have many Nagios probes. NDO is an abomination as is storing this kind of data in MySQL. Commercial tools are orders of magnitude worse.
- Monitoring logic is not reusable. Today with approaches like continuous deployment you need your monitoring logic to be reusable by many different parties. Deployers should be able to run the same logic on demand as your scheduled monitoring does.
- Configuration is a nightmare of static text, or worse click driven databases. People mitigate this with CM tools but there is still a long turn around time from node creation to monitored. This is not workable in modern cloud based and dynamic systems.
- Shops with skilled staff are constantly battling decades old tools if they want to extend it to create metrics driven infrastructure. It’s all just too ’90s.
- It does not scale. My simple prototype can easily do 300+ checks a second, including processing replies, archiving, alert logic and feeding external tools like Graphite. On a GBP20/month virtual machine. This is inconceivable with most of the tools we have to deal with.
I am prototyping some ideas at the moment to build a framework to build monitoring systems with.
There’s a single input queue on a middleware system, I expect an event in this queue – mine is a queue distributed over 3 countries and many instances of ActiveMQ.
The event can come from many places maybe from a commit hook at GitHub, fed in from Nagios performance data or by MCollective or Pingdom, the source of data is not important at all. It’s just a JSON document that has some structure – you can send in any data in addition to a few required fields, it’ll happily store the lot.
From there it gets saved into a capped collection on MongoDB in its entirety and gets given an eventid. It gets broken into its status parts and its metric parts and sent to any number of recipient queues. In the case of Metrics for example I have something that feeds Graphite, you can have many of these all active concurrently. Just write a small consumer for a queue in any language and do with the events whatever you want.
In the case of statusses it builds a MongoDB collection that represents the status of an event in relation to past statusses etc. This will notice any state transition and create alert events, alert events again can go to many destinations – right now I am sending them to Angelia, but there could be many destinations with different filtering and logic for how that happens. If you want to build something to alert based on trends of past metric data, no problem. Just write a small plugin, in any language, and plug it into the message flow.
At any point through this process the eventid is available and should you wish to get hold of the original full event its a simple lookup away – there you can find all the raw event data that you sent – stored for quick retrieval in a schemaless manner.
In effect this is a generic plugable event handling system. I currently feed it from MCollective using a modified NRPE agent and I am pushing my Nagios performance data in real time. I have many Nagios servers distributed globally and they all just drop events into a their nearest queue entry point.
Given that it’s all queued and persisted to disk I can create really vast amount of alerts using MCollective – it’s trivial for me to create 1000 check results a second. The events have the timestamp attached of when the check was done and even if the consumers are not keeping up the time series databases will get the events in the right order and right timestamps. So far on a small VM that runs Puppetmaster, MongoDB, ActiveMQ, Redmine and a lot of other stuff I am very comfortably sending 300 events a second through this process without even tuning or trying to scale it.
When I look at a graph of 50 servers load average I see the graph change at the same second for all nodes – because I have an exact single point in time view of my server estate, and what 50 servers I am monitoring in this manner is done using discovery on MCollective. Discovery is obviously no good for monitoring in general – you dont know the state of stuff you didn’t discover – but MCollective can build a database of truth using registration – correlate discovery against registration and you can easily identify missing things.
A free side effect of using an async queue is that horizontal scaling comes more or less for free, all I need to do is start more processes consuming the same queue – maybe even on a different physical server – and more capacity becomes available.
So this is a prototype, its not open source – I am undecided what I will do with it, but I am likely to post some more about its design and principals here. Right now I am only working on the event handling and routing aspects as the point in time monitoring is already solved for me as is my configuration of Nagios, but those aspects will be mixed into this system in time.
There’s a video of the prototype receiving monitor events over mcollective and feeding Loggly for alerts here.
