I develop ruby-pdns, so far things have been very static – you give it code and it serves your code, simple stuff.
But this is not what I want, I want a full API enabled DNS server where I can both code the logic for records as well as send environmental data into the DNS server to adjust it’s behavior.
I think there’s a big gap in the various cloud offerings today wrt to DNS, people end up hosting their DNS and make manual config changes, but this is not what clouds are about, you want to code the entire infrastructure, and it should adjust based on demand. This does not sit well with todays slow and generally crappy DNS. Combined with the fact that clouds don’t let you follow the time tested methods for load balancing etc. we need to get creative.
My end game then is to scratch this itch, you should be able to host DNS servers and interact with them fully both in how they decide how to answer requests but also send data to them and adjust the behaviors on the fly.
Version 1 of Ruby PDNS will hopefully achieve this, here is a video of what you might expect to be able to do – the video sends data to the DNS server telling it to take a machine out of the pool for maintenance. There will be REST based APIs that will enable any language to do this, if you want to play the code that you’ll see in the video is all in SVN.
I still have some ways to go before version 1, consider this a very early preview after 1 nights hacking on the feature.
I just released version 0.5 of Ruby PDNS. This mainly introduces a full statistics capability and fixes a minor bug or two.
I didn’t intend on releasing another version before 1.0 but it turns out the stats feature were quite a big job worthy of a release.
The stats is complicated by the fact that PDNS runs multiple instances of my code sharing the load between them, this makes keeping stats pretty hard because I have no shared memory space like you would in a multi threaded app. So I’d somehow need to dump per process stats and calculate totals. Everyone I asked suggested writing a log and summarizing the log data but this just never felt right to me – there would be issues with log rotation and knowing till when you last counted stats and so forth – so I kept looking for a solution.
I struggled to come up with a good approach for a long time, finally settling on each process writing a YAML file with it’s stats and a cron job to aggregate it regularly. This turned out to be quite elegant – much more so than processing logs for example – as the cron job cleans up files it already processed and also ignore too old ones etc. If the cron job keeps running it should be zero maintenance.
I added a script – pdns-get-stats.rb – to query the aggregated stats:
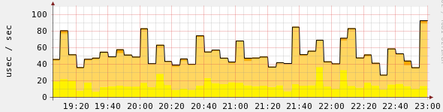
The puppet record is using GeoIP so you’d expect it to be a bit slower than ones that just shuffle records and this is clear above, though I am quite pleased with the performance of the GeoIP code. Times are in microseconds.
Those who know Cacti will recognise the format as being compatible with the Cacti plugin standard – if there is demand I can easily add Munin, Collectd etc query tools
Using the details I was able to draw a quick little graph below using Cacti
The next major step is to write a API that is externally accessible, perhaps using REST over HTTP, this means you could send data from your monitoring or CMDB and adjust weights or really anything you can code using external data.
Puppet supports something called Modules, it’s a convenient collection of templates, files, classes, types and facts all related to one thing. I find it makes it easy to think about a problem in an isolated manner and it should be the default structure everyone use.
Usually though the problem comes with how to lay out modules and how to really use the Puppet classes system, below a simple module layout that can grow with you as your needs extend. I should emphasis the simple here – this example does not cater well for environments with mix of Operating Systems, or weird multi site setups with overrides per environment, but once you understand the design behind this you should be able to grow it to cater for your needs. If you have more complex needs, see this post as a primer on using the class relationships effectively.
For the most part I find I make modules for each building block – apache, syslog, php, mysql – usually the kind of thing that has:
One or more packages – or at least some install process.
One or more config files or config actions
A service or something that you do to start it.
You can see there’s an implied dependency tree here, the config steps require the package to be installed and the service step require the config to be done. Similarly if any config changes the services might need to restart.
We’d want to cater for the case where you could have 10 config files, or 10 packages, or 100s of files needed to install the service in question. You really wouldn’t want to create a big array of require => resources to control the relationships or to do the notifications, this would be a maintenance nightmare.
We’re going to create a class for each of the major parts of the module – package, config and service. And we’ll use the class systems and relationships, notifies etc to ensure the ordering, requires and notifies are kept simple – especially so that future changes can be done in one place only without editing everywhere else that has requires.
If we now just do include ntp everything will happen cleanly and in order.
There’s a few things you should notice here. We’re using the following syntax in a few places:
require => Class[“ntp::something”]
notify => Class[“ntp::service”]
before => Class[“ntp::something”]
subscribe => Class[“ntp::config”]
All of the usual relationship meta parameters can operate on classes, so what this means is if you require Class[“ntp::config”] then both ntp.conf and step-tickers will be created before the service starts without having to list the files in your relationships. Similarly if you notify a class then all resources in that class gets notifies.
The preceding paragraph is very important to grasp, typically we’d try to maintain arrays of files in require trees and later if we add a new config file we have to go hunt everywhere that needs to require it and update those places, by using this organization approach we never have to update anything. If I add 10 services and 100 files into the config and service classes everything else that requires ntp::service will still work as expected without needing updates.
This is a very important decoupling of class contents with class function. Your other classes should never be concerned with class contents only class function.
As a convention this layout is a good sample, if all your daemons gets installed in the daemon::install class you’ll have no problem knowing where to find the code to adjust the install behavior – perhaps to upgrade to the next version – you should try to come up with a set of module naming conventions that works for you and stick to it throughout your manifests – I have a rake task to setup my usual module structure, they’re all the same and the learning curve for new people is small.
By building up small classes that focus on their task or subtask you can build up ever more powerful modules. We have a simple example here, but you can see how you could create ntp::master and ntp::client wrapper classes that would simply reuse the normal ntp::install and ntp::service classes.
As I mentioned this is a simple example for simple needs, the real take away here is to use class relationships and decouple the contents of those classes with their intent this should give you a more maintainable code set.
Ultimately conventions such as these will be needed to get us all one step closer to being able to share modules amongst each other as the specifics of making Apache on different distributions work will not matter – we’d just know that we want Class[“apache::service”] for example.
I use vim for almost all my editing needs, till now I often thought I should give using TextMate another try due to the nice Bundle that Masterzen made but there’s just something about desktop editing that puts me off.
I’ve also been renewing my efforts to better my VIM use and came across the excellent snipMate that enables you to do almost the same thing as textmate – the syntax for the snippets is even roughly the same.
I made a quick snippet file this morning for some common used bits that you can find here, see it in action below or view the movie better here:
Each time you see the input cursor jump between fields in the templates I’m simply pressing tab, shift-tab would cycle backward.
There are some nice things here you might not notice, for example editing a file test.pp and adding a class it will automatically fill in the class name as test. Same for nodes, it’s really very powerful and the snippets are trivial to write.
I am using the vim syntax file that comes in the puppet tarball and the adaryn color scheme that ships with vim.
Often while writing Puppet manifests you find yourself needing data, things like the local resolver, SMTP relay, SNMP Contact, Root Aliases etc. once you start thinking about it the amount of data you deal with is quite staggering.
It’s strange then that Puppet provides no way to work with this in a flexible way. By flexible I mean:
A way to easily retrieve it
A way to choose data per host, domain, location, data center or any other criteria you could possibly wish
A way to provide defaults that allow your code to degrade gracefully
A way to make it a critical error should expected data not exist
A way that works with LDAP nodes, External Nodes or normal node{} blocks
This is quite a list of requirements, and in vanilla puppet you’d need to use case statements, if statements etc.
For example, here’s a use case, set SNMP Contact and root user alias. Some machines for a specific client should have different contact details than other, indeed even some machines should have different contact details. There should be a fall back default value should nothing be set specifically for a host.
You might attempt to do this with case and if statements:
You can see that this might work, but it’s very unwieldy and your data is all over the code and soon enough you’ll be nesting selectors in case statements inside if statements, it’s totally unwieldy not to mention not reusable throughout your code.
Not only is it unwieldy but if you wish to add more specifics in the future you will need to use tools like grep, find etc to find all the cases in your code where you use this and update them all. You could of course come up with one file that contains all this logic but it would be aweful, I’ve tried it’s not viable.
What we really want to do is just this, and it should take care of all the code above, you should be able to call this wherever you want with complete disregard for the specifics of the overrides in data:
I’ve battled for ages with ways to deal with this and have come up with something that fits the bill perfectly, been using it and promoting it for almost a year now and so far found it to be totally life saver.
Sticking with the example above, first we should configure a lookup order that will work for us, here is my actual use:
This sets up the lookup code to first look for data specified for the host, then the location the host is hosted at, then the domain, country and eventually a set of defaults.
My current version of this code uses CSV files to store the data simply because it was convenient and universally available with no barrier to entry. It would be trivial to extend the code to use a database, LDAP or other system like that.
For my example if I put into the file some.box.your.com.csv the following:
The lookup code will use this data whenever extlookup(“contactemail”) gets called on that machine, but will use the default when called from other hosts. If you follow the logic above you’ll see this completely replace the case statement above with simple data files.
Using a system like this you can model all your data needs and deal with the data and your location, machine, domain etc specific data outside of your manifests.
The code is very flexible, you can reuse existing variables in your code inside your data, for example:
In this case if you have $country defined in your manifest the code will use this variable and put it into the answer. This snippet of data also shows that it supports arrays.
This code will ensure that, unless otherwise specified, I do not want to have screen installed on any of my servers. I could now though decide that all machines in a domain, or all machines in a location, country or specific hosts could have screen installed by simply setting them to present in the data file.
This makes the code not only configurable but configurable in a way that suits every possible case as it depends on the precedence defined above. If your use case does not rely on countries for example you can just replace the country ordering with whatever works for you.
I use this code in all my manifests and it’s helped me to make an extremely configurable set of manifests. It has proven to be very flexible as I can use the same code for different clients in different industries and with different needs and network layouts without changing the code.
Yesterday I released version 0.4 of my Ruby PowerDNS development framework.
Version 0.3 was a feature complete version but lacked in some decent error handling in all cases which resulted in weird unexplained crashes when things didn’t work as hoped, for example syntax errors in records could kill the whole thing.
Version 0.4 is a big push in stability, I’ve added tons of exception handling there should now be very few cases of unexpected terminations, I know of only one case and that’s when the log can’t be written too, all other cases should be logged and recovered from in some hopefully sane way.
I’ve written loads of unit tests using Test::Unit and have created a little testing harness that can be used to test your records without putting them on the server, using this for example you can test GeoIP based records easily since you can specify any source address.
Overall I think this is a production ready release, it would be a 1.0 release was it not for some features I wish to add before calling it 1.0. The features are about logging stats and about consuming data from external sources, these will be my next priorities.