by R.I. Pienaar | Jun 23, 2012 | Code
This ia a post in a series of posts I am doing about MCollective 2.0 and later.
In the past discovery was reasonably functional, certainly at the time I first demoed it around 2009 it was very unique. Now other discovery frameworks exist that does all sorts of interesting things and so we did 3 huge improvements to discovery in MCollective that again puts it apart from the rest, these are:
- Complex discovery language with full boolean support etc
- Plugins that lets you query any node data as discovery sources
- Plugins that lets you use any data available to the client as discovery sources
I’ll focus on the first one today. A quick example will be best.
$ mco service restart httpd -S "((customer=acme and environment=staging) or environment=development) and /apache/" |
$ mco service restart httpd -S "((customer=acme and environment=staging) or environment=development) and /apache/"
Here we are a hypothetical hosting company and we want to restart all the apache services for development. One of the customers though use their staging environment as development so it’s a bit more complex. This discovery query will find the acme customers staging environment and development for everyone else and then select the apache machines out of those.
You can also do excludes and some other bits, these 2 statements are identical:
$ mco find -S "environment=development and !customer=acme"
$ mco find -S "environment=development and not customer=acme" |
$ mco find -S "environment=development and !customer=acme"
$ mco find -S "environment=development and not customer=acme"
This basic form of the language can be described with the EBNF below:
compound = ["("] expression [")"] {["("] expression [")"]}
expression = [!|not]statement ["and"|"or"] [!|not] statement
char = A-Z | a-z | < | > | => | =< | _ | - |* | / { A-Z | a-z | < | > | => | =< | _ | - | * | / | }
int = 0|1|2|3|4|5|6|7|8|9{|0|1|2|3|4|5|6|7|8|9|0} |
compound = ["("] expression [")"] {["("] expression [")"]}
expression = [!|not]statement ["and"|"or"] [!|not] statement
char = A-Z | a-z | < | > | => | =< | _ | - |* | / { A-Z | a-z | < | > | => | =< | _ | - | * | / | }
int = 0|1|2|3|4|5|6|7|8|9{|0|1|2|3|4|5|6|7|8|9|0}
It’s been extended since but more on that below and in a future post.
It’s very easy to use this filter in your code, here’s a Ruby script that sets the same compound filter and restarts apache:
#!/usr/bin/ruby
require "mcollective"
include MCollective::RPC
c = rpcclient("service")
c.compound_filter '((customer=acme and environment=staging) or environment=development) and /apache/'
printrpc c.restart(:service => "httpd") |
#!/usr/bin/ruby
require "mcollective"
include MCollective::RPC
c = rpcclient("service")
c.compound_filter '((customer=acme and environment=staging) or environment=development) and /apache/'
printrpc c.restart(:service => "httpd")
These filters are combined with other filters so you’re welcome to mix in Identity filters etc using the other filter types and they will be evaluated additively.
These filters also supports querying node data, a simple example of such a query can be seen here:
$ mco service restart httpd -S "fstat('/etc/httpd/conf/httpd.conf').md5 = /51b08b8/" |
$ mco service restart httpd -S "fstat('/etc/httpd/conf/httpd.conf').md5 = /51b08b8/"
This will match all machines with a certain MD5 hash for the apache config file and restart them. More on these plugins the next post where I’ll show you how to write your own and use them.
by R.I. Pienaar | Jun 19, 2012 | Code, Uncategorized
As mentioned in my first post in this series I will be covering new MCollective features that were introduced with version 2.0.0 or later. Today I’ll talk about the biggest new feature called Direct Addressing.
The Past – Broadcast Only Mode
In the past MCollective only had one mode of communication. It would send a broadcast message to all nodes with the target agent in a named group (subcollective) and this message would have a filter attached that nodes will validate to determine if they should run the action. Basically if I send a message with a filter “country=uk” all machines will get it and validate this filter, the ones that match will act on the message.
This mode is the first problem I set out to solve – a way to have a broadcast based zero config RPC system that can address many machines in parallel with a new style of addressing. I wanted to get the broadcast model right first and I wanted to get the RPC structures right as well before looking at other possibilities.
There were many 1:1 RPC systems before and it’s not a very hard problem to solve if you have a queue – but it was not the problem I set out to solve as my first target. MCollective 1.2.1 and older did not have a 1:1 mode.
The parallel mode works fine in many scenarios, specifically this is the only real way to build a central coordinator that degrades well in split brain scenarios since addressing is done by discovery and only discovered nodes are expected to reply. It’s a new paradigm – one thats better suited for distributed applications since failure is inevitable you may as well code your applications to always work in that environment.
I think MCollective solved that problem well in the past but the very nature of that mode of communication means it is not suitable for all use cases. The unsuitable usage include some of the points below but there are of course others:
- If you want to deploy to a pre-determined set of hosts you really want to be sure they get your request and get warnings if they dont
- The broadcast mode is very fast and parallel, you might want to do rolling restarts
- The broadcast only operates with a concept of now, you might know a machine is being provisioned and soon as its up you want it to run your command that you sent 10 minutes ago
- Your discovery needs might not map onto what MCollective support, like when you present users with a host list they can pick arbitrary hosts from
There are many similar problems that was awkward to fit into the MCollective model in the past, all related to either trying to live outside its idea of addressing or about slowing it down to a pace suitable for rolling changes.
Messaging Rewrite
As of 2.0.0 we now have a fairly large rewrite of the messaging subsystem to be more generic and extendable but it also introduce a new mode of addressing that allows you to provide the host list in any way you want. Rather than doing a broadcast for these requests it will communicate only with the specified nodes.
The history of MCollective is that it used to be a in-house unpublished project that was made pluggable and open sourced. The initial release did a OK job of it but the messaging had a bunch of badly coupled decisions all over the code base that was a legacy left over. In 2.0.0 we’re rewritten all of this and abstracted all the actual communication with the middleware away from MCollective core. This made it much easier to change how we approach messaging.
Armed with the 2nd mode of communication we were able to apply the very same existing RPC system to a second more traditional style of addressing and we’re able to mix and match freely between these modes when appropriate. In 2.0.0 this is all kind of under the covers and accessible to the API only but in the new development series – 2.1.x – there has already been a bunch of new user facing features added thanks to this new mode.
Best is to show some code, here’s a traditional discovery based approach to running and action against some machines. The example will just restart apache on some machines:
c = rpcclient("service")
c.fact_filter "country=uk"
printrpc c.restart(:service => "httpd") |
c = rpcclient("service")
c.fact_filter "country=uk"
printrpc c.restart(:service => "httpd")
This code sets the fact_filter which it will get via discovery and then communicates with those hosts. You’re basically here at the mercy of the network and current status of those machines for which ones will be affected.
But what if you had a list of hosts that you know you wanted to target like you would if you’re doing a specific deployment task? You’d have had to do something like:
c.identity_filter /^host1|host2|host3|host4$/ |
c.identity_filter /^host1|host2|host3|host4$/
Instead of the fact filter, not ideal! It would still be doing a discover and should host4 not be around it will not really tell you it can’t talk to 4. All it knows is there’s a regex to match.
Now since MCollective 2.0.0 the situation is hugely improved, here’s the client again this time supplying custom discovery data:
c = rpcclient("service")
c.discover :nodes => File.readline("hosts.txt").map {|i| i.chomp}
printrpc c.restart(:service => "httpd")
unless c.stats.noresponsefrom.empty?
STDERR.puts "WARNING: No responses from hosts: %s" % [c.stats.noresponsefrom.join(", ")]
end |
c = rpcclient("service")
c.discover :nodes => File.readline("hosts.txt").map {|i| i.chomp}
printrpc c.restart(:service => "httpd")
unless c.stats.noresponsefrom.empty?
STDERR.puts "WARNING: No responses from hosts: %s" % [c.stats.noresponsefrom.join(", ")]
end
In this example I am reading a text file called hosts.txt that should have 1 hostname per line and passing that into the discover method. This switches the MCollective client into Direct Addressing mode and it will attempt to communicate with just the hosts you provided in the host list.
Communication is still via the Message Broker even in direct mode but under the covers this is built using queues.
Now if any of those hosts aren’t responding in time you will get an actual useful error message that you could handle in your code in whatever way you wish.
Also note that we were not compelled to construct a filter that would match every host like in the past, just giving the list of identities were enough.
This is a lot more suitable for the purpose of building deployment tools or web applications where you might have arbitrary hosts. This also demonstrates that you are effectively doing discovery against a text file and can easily be adapted to communicate with a database or any data you might have on the client side.
Other Possibilities
This mode opens up a whole bunch of possibilities and I’ll run through a few here – and there will be follow up posts covering some of these in more detail:
Command Chaining
You can now chain RPC requests via Unix pipes:
% mco rpc package status package=foo -j | jgrep data.version=1.2.3 | mco rpc puppetd runonce |
% mco rpc package status package=foo -j | jgrep data.version=1.2.3 | mco rpc puppetd runonce
This fetches the package version of the foo package, filters out only the nodes where the version is 1.2.3 and then does a Puppet run on those nodes. The Puppet run is using the filtered result set from the first command as a source of discovery information so you do not need to supply any filters or anything like that.
Batched Requests
To avoid affecting all discovered nodes at the same time you can now do things in smaller batches, carving up the total discovered nodes into smaller chunks:
% mco rpc service restart service=httpd --batch=2 --batch-sleep=60 |
% mco rpc service restart service=httpd --batch=2 --batch-sleep=60
This will look on the surface the exact same as before, progress bar and all, but it will progress in groups of 2 and sleep a minute between each group. It will still be traditional discovery (Unless you use -I), the results will look the same, everything will be the same except it will just affect 2 machines at a time.
You can ^C at any time to bail out and only the batches up to that point will be affected.
Traffic Optimization
If you have a 1000 nodes and you often just communicate with a small amount – say 10 – the broadcast mode is not very efficient, the middleware will shunt messages to all 1000 all the time.
Since 2.0.0 the client will switch to Direct Addressing mode if it determines you are communicating with No discovery for identity only filters
If you are only using the -I option and not supplying regular expressions MCollective will now switch to direct addressing mode and just assume you know what you’re doing.
% mco rpc rpcutil ping -I devco.net
* [============================================================> ] 1 / 1
devco.net
Timestamp: 1340117924
Finished processing 1 / 1 hosts in 62.17 ms |
% mco rpc rpcutil ping -I devco.net
* [============================================================> ] 1 / 1
devco.net
Timestamp: 1340117924
Finished processing 1 / 1 hosts in 62.17 ms
Note there’s no indication that it’s doing any discovery – that’s because it completely bypassed that step, you can specify multiple -I arguments to go out to many machines.
The total runtime here will be very close to 70ms vs the old 2 seconds for discovery and 70ms for the main request.
Pluggable Discovery
Now that we can get host lists from anywhere we’ve made discovery completely pluggable allowing you to decide what is your preferred source of truth that suits your needs best.
Here are some examples:
Query a flatfile:
% mco rpc service restart service=httpd --nodes=hosts.txt |
% mco rpc service restart service=httpd --nodes=hosts.txt
Discover using data kept in PuppetDB:
% mco rpc service restart service=httpd -W country=uk --dm=puppetdb |
% mco rpc service restart service=httpd -W country=uk --dm=puppetdb
There are plugins for flatfiles, PuppetDB, MongoDB as built by registration, old style broadcast mode (the default) and more will be written like a recent one by a community member that queries Elastic Search. Imagine discovering against Zookeeper, Chef Server, Noah or any other data source you can imagine. Direct Addressing makes all of that possible.
This is a MCollective 2.1.x feature only at the moment so still maturing in the development series.
Message TTLs
Directly addressed messages are implemented using queues, this means they can linger on the network when no-one is there to consume them. Using this feature we can send RPC requests to nodes that do not exist yet – time band that request and should the node become active during the TTL they will act on that request:
% mco rpc service restart service=httpd --ttl 1000 -I some.node |
% mco rpc service restart service=httpd --ttl 1000 -I some.node
This request will go sit in the queue for some.node and if that machine boots up in the next 1000 seconds it will perform the request. The TTLs are low by default and it does mean your clocks need to be synced. RPC to non existing hosts though, quite interesting bootstrapping possibilities.
Entirely new styles of application built ontop of MCollective
Now that the MCollective messaging has been abstracted out of core it would be fairly easy to apply MCollective to non request/response style systems. We can use MCollective libraries to just transport arbitrary data between 2 processes. This will be done using the security, serialization and connector plugins meaning that you can write generic code and just reuse my libraries to have pluggable security and network capabilities.
The system now supports sending requests and reading the replies elsewhere. For a web based system this would allow a 100% async model. You could send your request from the web page and have the replies spool into a temporary storage like a NoSQL database where you show the result sets using paging and traditional web approaches. This combined with arbitrary discovery sources means an entirely new kind of web application can be built using MCollective RPC that’s very fast, responsive and feature rich
Conclusion
That’s a quick intro to the new messaging rewrite covering just a few areas it’s already improved. I’ll follow up with more in depth blog posts about some of the items mentioned above.
Having this mode doesn’t deprecate or invalidate the older broadcast mode, I still believe this is the right approach for zero config systems, still believe its method of degrading is the right way to build a certain kind of application and MCollective will remain suitable to those kinds of application. It will remain the default mode for a freshly installed MCollective client. The new mode enhances the existing capabilities.
A side effect of all of this rewriting is that the connectivity plugin is now in full control of how this is implemented paving the way for wider middleware support in the future. At the moment the only viable way to use this feature is to use ActiveMQ but we’ll add more plugins in the future.
Given the above statement Direct Addressing isn’t yet enabled by default but expect that to change in the next major release.
by R.I. Pienaar | Jun 16, 2012 | Code
It’s been a long time since I wrote any blog posts about MCollective, I’ll be rectifying that by writing a big series of blog posts over the next weeks or months.
MCollective 2.0 was recently released and it represents a massive internal restructure and improvement cycle. In 2.0 not a lof of the new functionality is visible immediately on the command line but the infrastructure now exist to innovate quite rapidly in areas of resource discovery and management. The API has had a lot of new capabilities added that allows MCollective to be used in many new use cases as well as improving on some older ones.
Networking and Addressing has been completely rewritten and reinvented to be both more powerful and more generic. You can now use MCollective in ways that were previously not possible or unsuitable for certain use cases, it is even more performant and more pluggable. Other parts of the ecosystem like ActiveMQ and the STOMP protocol has had major improvements and MCollective is utilising these improvements to further its capabilities.
The process of exposing new features based on this infrastructure rewrite to the end user has now started. Puppet Labs have recently released version 2.1.0 which is the first in a new development cycle and this release have hugely improved the capabilities of the discovery system – you can now literally discover against any conceivable source of data on either the client side or out on your network or a mix of both. You can choose when you want current network conditions to be your source of truth or supply the source of truth from any data source you might have. In addition an entirely new style of addressing and message delivery has been introduced that creates many new usage opportunities.
The development pace of MCollective has taken a big leap forward, I am now full time employed by Puppet Labs and working on MCollective. Future development is secure and the team behind is growing as we look at expending it’s feature set.
I’ll start with a bit of a refresher about MCollective for those new to it or those who looked in the past at but maybe want to come back for another look. In the coming weeks I’ll follow up with a deeper look into some of the aspects highlighted below and also the new features introduced since 2.0.0 came out.
Version 2.0 represents a revolutionary change to MCollective so there is lots of ground to cover each blog post in the series will focus on one aspect of the new features and capabilities.
The Problem
Modern systems management has moved on from just managing machines with some reasonably limited set of software on them to being a really large challenge in integrating many different systems together. More and more the kinds of applications we are required to support are made up of many internal components spread across 100s of machines in ever increasing complexity. We are now Integration Experts above all – integrate legacy systems with cloud ones, manage hi-brid public and private clouds, integrate external APIs with in house developed software and often using cutting edge technologies that tend to be very volatile. Today we might be building our infrastructure on some new technology that does not exist tomorrow.
Worse still the days of having a carefully crafted network that’s a known entity with individually tuned BIOS settings and hand compiled kernels is now in the distant past. Instead we have machines being created on demand and shutdown when the demand for their resources have passed. Yet we still need to be able to manage them, monitor them and configure them. The reality of a platform where at some point of the day it can be 200 nodes big and later on the same day it can be 50 nodes has invalidated many if not most of our trusted technologies like monitoring, management, dns and even asset tracking.
Developers have had tools that allow them to cope with this ever changing landscape by abstracting the communications between 2 entities via a well defined interface. Using an interface to define a communications contract between component A and component B means if we later wish to swap out B for C that if we’re able to create a wrapper around C that complies to the published interface we’ll be able to contain the fallout from a major technology change. They’ve had more dynamic service registries that’s much more capable of coping with change or failure than the older rigid approach to IT management afforded.
Systems Administrators has some of this in that most of our protocols are defined in RFCs and we can generally assume that it would be feasible to swap one SMTP server for another. But what about the management of the actual mail server software in question? You would have dashboards, monitoring, queue management, alerting on message rates, trend analysis to assist in capacity planning. You would have APIs to create new domains, users or mail boxes in the mail system often accessed directly by frontend web dashboards accessible by end users. You would expose all or some of these to various parts of your business such as your NOC, Systems Operators and other technical people who have a stake in the mail systems.
The cost of changing your SMTP server is in fact huge and the fact that the old and new server both speak SMTP is just a small part of the equation as all your monitoring, management capability and integration with other systems will need to be redeveloped often resulting in changes in how you manage those systems leading to retraining of staff and a cycle of higher than expected rate of human error. The situation is much worse if you had to run a heterogeneous environment made up of SMTP software from multiple vendors.
In very complex environments where many subsystems and teams would interact with the mail system you might find yourself with a large mixture of Authentication Methods, Protocols, User Identities, Auditing and Authorization – if you’re lucky to have them at all. You might end up with a plethora of systems from front-end web applications to NOCs or even mobile workforce all having some form of privileged access to the systems under management – often point to point requiring careful configuration management. Managing this big collection of AAA methods and network ACL controls is very complex often leading to environments with weak AAA management that are almost impossible to make compliant to systems like PCI or SOX.
A Possible Solution
One part of a solution to these problems is a strong integration framework. One that provides always present yet pluggable AAA. One that lets you easily add new capabilities to the network in a way that is done via a contract between the various systems enabling networks made up of heterogeneous software stacks. One where interacting with these capabilities can be done with ease from the CLI, Web or other mediums and that remains consistent in UX as your needs change or expand.
You need novel ways to address your machines that are both dynamic and rigid when appropriate. You need a platform thats reactive to change, stable yet capable of operating sanely in degraded networking conditions. You need a framework that’s capable of doing the simplest task on a remote node such as running a single command to being the platform you might use to build a cloud controller for your own PAAS.
MCollective is such an framework aimed at the Systems Integrator. It’s used by people just interacting with it on a web UI to do defined tasks to commercial PAAS vendors using it as the basis of their cloud management. There are private clouds built using MCollective and libvirt that manages 100s of dom0s controlling many more virtual machines. It’s used in many industries solving a wide range of integration problems.
The demos you might have seen have usually been focussed on CLI based command and control but it’s more than that – CLIs are easy to demo, long running background orchestration of communication between software subsystems is much harder to demo. As a command and control channel for the CLI MCollective shines and is a pleasure to use but MCollective is an integration framework that has all the components you might find in larger enterprise integration systems, these include:
- Resource discovery and addressing
- Flexible registration system capable of building CMDBs, Asset Systems or any kind of resource tracker
- Contract based interfaces between client and servers
- Strong introspective abilities to facilitate generic user interfaces
- Strong input validation on both clients and servers for maximum protection
- Pluggable AAA that allows you to change or upgrade your security independant of your code
- Overlay networking based on Message Orientated Middleware where no 2 components require direct point to point communications
- Industry standard security via standard SSL as delivered by OpenSSL based on published protocols like STOMP and TLS
- Auto generating documentation
- Auto generating packaging for system components that’s versioned and managed using your OS capabilities without reinventing packaging into yet another package format
- Auto generating code using generators to promote a single consistant approach to designing network components
MCollective is built as distributed system utilising Message Orientated Middleware. It presents a Remote Procedure Call based interface between your code and the network. Unlike other RPC systems it’s a parallel RPC system where a single RPC call can affect one or many nodes at nearly the same time affording great scale, performance and flexibility – while still maintaining a more traditional rolling request cycle approach.
Distributed systems are hard, designing software to be hosted across a large number of hosts is difficult. MCollective provides a series of standards, conventions and enforced relationships that when embraced allow you to rapidly write code and run it across your network. Code that do not need to be aware of the complexities of AAA, addressing, network protocols or where clients are connecting from – these are handled by layers around your code.
MCollective specifically is designed for your productivity and joy – these are the ever present benchmarks every feature is put against before merging. It uses the Ruby language that’s very expressive and easy to pick up. It has a bunch of built in error handling that tend to do just the right thing and when used correctly you will almost never need to write a user interface – but when you do need custom user interfaces it provides a easy to use approach for doing so full of helpers and convention to make it easy to create a consistant experience for your software.
How to design interaction between loosely coupled systems is often a question people struggle with, MCollective provides a single way to design the components and provides a generic way to interact with those components. This means as a Systems Integrator you can focus on your task at hand and not be sucked into the complexities of designing message passing, serialization and other esoteric components of distributed systems. But it does not restrict you to the choices we made as framework developers as almost every possible components of MCollective is pluggable from network transport, encryption systems, AAA, serializers and even the entire RPC system can be replaced or complimented by different one that meets your needs.
The code base is meticulously written to be friendly, obvious and welcoming to newcomers to this style of programming or even the Ruby language. The style is consistant throughout, the code is laid out in a very obvious manner and commented where needed. You should not have a problem just reading the code base to learn how it works under the hood. Where possible we avoid meta programming and techniques that distract from the readability of the code. This coding style is a specific goal and required for this kind of software and an aspect we get complimented on weekly.
You can now find it pre-packaged in various distributions such as Ubuntu, Fedora and RHEL via EPEL. It’s known to run on many platforms and different versions of Ruby and has even been embedded into Java systems or ran on iPhones.
Posts in this series
This series is still being written, posts will be added here as they get written:
by R.I. Pienaar | Apr 29, 2012 | Code
 A few weeks ago I blogged about my TODO / Reminder project called gwtf, I’ve done a lot since then and thought I’ll give a quick progress update.
A few weeks ago I blogged about my TODO / Reminder project called gwtf, I’ve done a lot since then and thought I’ll give a quick progress update.
Generally I am very glad I started this process, I am actually continuing to use it today which is probably the longest I’ve ever used any TODO or reminder application. It really is good to be able to hack your own workflow and have a tool you can adapt to your needs rather than try to fit the mold of some off the shelf tool.
The time tracking feature has proven very valuable – as I work on my various projects I will track time worked with gwtf and review my mental estimate at the end of adding a feature. In time I am sure this will improve my ability to provide accurate time estimates while coding something for work etc.
The big thing I’ve added is a reminder system that can send notifications via email, boxcar or notifo (community contributed method). The image show my iPhone receiving a push message. All items can have a reminder date and in line with the Unix CLI approach this is done using your system at(1) command. Each notification can go to multiple recipients so I get email and push notifications.
% gwtf new this is a test --remind="now + 1 week" --done --ifopen
Creating reminder at job for item 30: job 46 at 2012-03-13 20:09
30 this is a test |
% gwtf new this is a test --remind="now + 1 week" --done --ifopen
Creating reminder at job for item 30: job 46 at 2012-03-13 20:09
30 this is a test
Here I will get a reminder a week from now after reminding the item will be marked as done. The reminder will only be sent if item has not already been closed.
Building on this I added a special project called reminders that does not show up in the normal list output, this project is where simple one-off reminders (and soon repeating ones) go. Being hidden from the list output means I can have many of them without feeling like I have a huge TODO backlog since these aren’t strictly TODO items.
% gwtf remind --at="now +1 hour" do something
Creating reminder at job for item 84: job 66 at 2012-04-10 15:11
103 L 2012-04-13 do something |
% gwtf remind --at="now +1 hour" do something
Creating reminder at job for item 84: job 66 at 2012-04-10 15:11
103 L 2012-04-13 do something
Items now have due dates and there is a notification method that will email you all due and overdue tasks. I find if my todo list get mailed to me every day I get blind to it real quick, by only mailing due and overdue items they stand out and I pay them attention.
Various item list commands have been added. When I log into my shell I get the following, the colors show me that the projects have items due soon, it would go red when they are overdue.
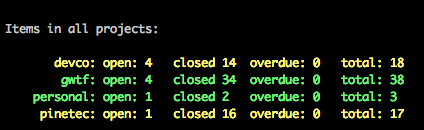
I’ve added an overview mode to the list command that shows all projects and their open items, again color coded as above.
I’ve also augmented all the date processing using the excellent Chronic gem. This means anywhere I need a date or time specification I can use natural language dates. For example the due date specification can be as simple as –due=”next week” which would end up being due on next Wednesday. I can be more specific like –due=”7pm next tuesday” etc. I really like this mode of date input since I almost never know what the date is anyway it’s a big challenge to type in full dates for this kind of system.
That’s the big ticket items but there has been a ton of small tweaks. Overall I’ve done 16 releases of the Gem and it’s been downloaded 1600+ times from rubygems.org. I put a little website up for it using the new GitHub site system with full documentation etc.
I am not sure who the 1600 downloaders are, I am certainly not developing this with other peoples needs in mind but hopefully someone is gaining value from it.
by R.I. Pienaar | Apr 28, 2012 | Code
Since shutting down my business I now run a small 25 node network with no Puppet Masters and I do not schedule regular Puppet runs – I run them just when needed.
Till now I’ve just done puppet runs via MCollective, basically I’d edit some puppet files and after comitting them just send off a puppet run with mcollective, supplying filters by hand so I only trigger runs on the appropriate nodes.
I started looking into git commit hooks to see if I can streamline this. I could of course just trigger a run on all nodes after a commit, there is no problem with capacity of masters etc to worry about. This is not very elegant so I thought I’d write something to parse my git push and trigger runs on just the right machines.
I’ll show a simplified version of the code here, the full version of the post-receive hook can be found here. I’ve removed the parse_hiera, parse_node and parse_modules functions from this but you can find them in the code linked to. To use this code you will need MCollective 2.0.0 that is due in a few days.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
|
#!/usr/bin/env ruby
require 'rubygems'
require 'grit'
require 'mcollective'
include MCollective::RPC
@matched_modules = []
@matched_nodes = []
@matched_facts = []
# read each git ref in the push and process them
while msg = gets
old_sha, new_sha, ref = msg.split(' ', 3)
repo = Grit::Repo.new(File.join(File.dirname(__FILE__), '..'))
commit = repo.commit(new_sha)
case ref
when %r{^refs/heads/(.*)$}
branch = $~[1]
if branch == "master"
puts "Commit on #{branch}"
commit.diffs.each do |diff|
puts " %s" % diff.b_path
# parse the paths and save them to the @matched_* arrays
# these functions are in the full code paste linked to above
case diff.b_path
when /^hieradb/
parse_hiera(diff.b_path)
when /^nodes/
parse_node(diff.b_path)
when /^common\/modules/
parse_modules(diff.b_path)
else
puts "ERROR: Do not know how to parse #{diff.b_path}"
end
end
else
puts "Commit on non master branch #{branch} ignoring"
end
end
end
unless @matched_modules.empty? && @matched_nodes.empty? && @matched_facts.empty?
puppet = rpcclient("puppetd")
nodes = []
compound_filter = []
nodes << @matched_nodes
# if classes or facts are found then do a discover
unless @matched_modules.empty? && @matched_facts.empty?
compound_filter << @matched_modules << @matched_facts
puppet.comound_filter compound_filter.flatten.uniq.join(" or ")
nodes << puppet.discover
end
if nodes.flatten.uniq.empty?
puts "No nodes discovered via mcollective or in commits"
exit
end
# use new mc 2.0.0 pluggable discovery to supply node list
# thats a combination of data discovered on the network and file named
puppet.discover :nodes => nodes.flatten.uniq
puts
puts "Files matched classes: %s" % @matched_modules.join(", ") unless @matched_modules.empty?
puts "Files matched nodes: %s" % @matched_nodes.join(", ") unless @matched_nodes.empty?
puts "Files matched facts: %s" % @matched_facts.join(", ") unless @matched_facts.empty?
puts
puts "Triggering puppet runs on the following nodes:"
puts
puppet.discover.in_groups_of(3) do |nodes|
puts " %-20s %-20s %-20s" % nodes
end
puppet.runonce
printrpcstats
else
puts "ERROR: Could not determine a list of nodes to run"
end |
#!/usr/bin/env ruby
require 'rubygems'
require 'grit'
require 'mcollective'
include MCollective::RPC
@matched_modules = []
@matched_nodes = []
@matched_facts = []
# read each git ref in the push and process them
while msg = gets
old_sha, new_sha, ref = msg.split(' ', 3)
repo = Grit::Repo.new(File.join(File.dirname(__FILE__), '..'))
commit = repo.commit(new_sha)
case ref
when %r{^refs/heads/(.*)$}
branch = $~[1]
if branch == "master"
puts "Commit on #{branch}"
commit.diffs.each do |diff|
puts " %s" % diff.b_path
# parse the paths and save them to the @matched_* arrays
# these functions are in the full code paste linked to above
case diff.b_path
when /^hieradb/
parse_hiera(diff.b_path)
when /^nodes/
parse_node(diff.b_path)
when /^common\/modules/
parse_modules(diff.b_path)
else
puts "ERROR: Do not know how to parse #{diff.b_path}"
end
end
else
puts "Commit on non master branch #{branch} ignoring"
end
end
end
unless @matched_modules.empty? && @matched_nodes.empty? && @matched_facts.empty?
puppet = rpcclient("puppetd")
nodes = []
compound_filter = []
nodes << @matched_nodes
# if classes or facts are found then do a discover
unless @matched_modules.empty? && @matched_facts.empty?
compound_filter << @matched_modules << @matched_facts
puppet.comound_filter compound_filter.flatten.uniq.join(" or ")
nodes << puppet.discover
end
if nodes.flatten.uniq.empty?
puts "No nodes discovered via mcollective or in commits"
exit
end
# use new mc 2.0.0 pluggable discovery to supply node list
# thats a combination of data discovered on the network and file named
puppet.discover :nodes => nodes.flatten.uniq
puts
puts "Files matched classes: %s" % @matched_modules.join(", ") unless @matched_modules.empty?
puts "Files matched nodes: %s" % @matched_nodes.join(", ") unless @matched_nodes.empty?
puts "Files matched facts: %s" % @matched_facts.join(", ") unless @matched_facts.empty?
puts
puts "Triggering puppet runs on the following nodes:"
puts
puppet.discover.in_groups_of(3) do |nodes|
puts " %-20s %-20s %-20s" % nodes
end
puppet.runonce
printrpcstats
else
puts "ERROR: Could not determine a list of nodes to run"
end
The code between lines 14 and 46 just reads each line of the git post-receive hook STDIN and process them, you can read more about these hooks @ git-scm.com.
For each b path in the commit I parse its path based on puppet module conventions, node names, my hiera structure and some specific aspects of my file layouts. These end up in the @matched_modules, @matched_nodes and @matched_facts arrays.
MCollective 2.0.0 will let you supply node names not just from network based discovery but from any source really. Here I get node names from things like my node files, file names in iptables rules and such. Version 2.0.0 also supports a new query language for discovery which we use here. The goal is to do a network discovery only when I have non specific data like class names – if I found just a list of node names I do not need to do go out to the network to do discovery thanks to the new abilities of MCollective 2.0.0
In lines 48 to 90 I create a MCollective client to the puppetd agent, discover matching nodes and do the puppet runs.
If I found any code in the git push that matched either classes or facts I need to do a full MCollective discover based on those to get a node list. This is done using the new compound filtering language, the filter will look something like:
/some_class/ or some::other::class or fact=value |
/some_class/ or some::other::class or fact=value
But this expensive network wide discovery is only run when there are facts or classes matched out of the commit.
Line 72 will supply the combined MCollective discovered nodes and node names discovered out of the code paths as discovery data which later in line 85 will get used to trigger the runs.
The end result of this can be seen here, the commit matched only 5 out of my 25 machines and only those will be run:
$ git push origin master
Counting objects: 13, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (6/6), done.
Writing objects: 100% (7/7), 577 bytes, done.
Total 7 (delta 4), reused 0 (delta 0)
remote: Commit on master
remote: common/modules/mcollective/manifests/client.pp
remote:
remote: Files matched classes: mcollective::client
remote:
remote: Triggering puppet runs on the following nodes:
remote:
remote: node1 node2 node3
remote: node4 node5
remote:
remote: 5 / 5
remote:
remote: Finished processing 5 / 5 hosts in 522.15 ms
To git@git:puppet.git
7590a60..10ee4da master -> master |
$ git push origin master
Counting objects: 13, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (6/6), done.
Writing objects: 100% (7/7), 577 bytes, done.
Total 7 (delta 4), reused 0 (delta 0)
remote: Commit on master
remote: common/modules/mcollective/manifests/client.pp
remote:
remote: Files matched classes: mcollective::client
remote:
remote: Triggering puppet runs on the following nodes:
remote:
remote: node1 node2 node3
remote: node4 node5
remote:
remote: 5 / 5
remote:
remote: Finished processing 5 / 5 hosts in 522.15 ms
To git@git:puppet.git
7590a60..10ee4da master -> master
